I'm working on a demo to show .NET ( C# ) code on Linux. As you all know, with the new cross-plat .NET execution context DNX that also run on Linux - this should be a breeze. So - let's see what it takes to make .NET run on your Linux machine.
First of all - you need to install the .NET version manager (DNVM) on your machine, which is really simple to do:
I've put up a script on GitHub that will do all of this for you:
https://github.com/jochenvw/arm_sandbox/blob/master/ubuntu-aspnetcore/ubuntu_aspnetcore.sh
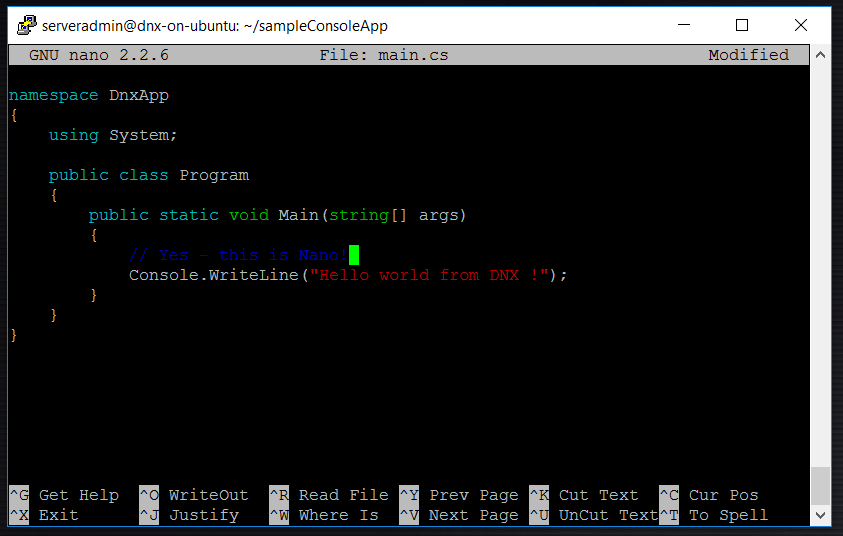
Also, in this script I create a main.cs file with the 'Hello World' console command.
Indeed - this is C# in Nano on Ubuntu. Pretty cool huh? I've found Nano syntax highlighting for C# - which is probably very similair to JAVA highlighting.
Anyway - after that - you just verify that you've got a DNX installed - do a package restore with the DNX utitility tool (dnu), do a 'dnu build' and then a 'dnx run' to run your application:
I'm making this setup script work unattended with the Azure ARM CustomScript extensions so that you can one-click-deploy a Linux box with DNX installed and this application up-and-running. Then I'll make a pull request for the previously mentioned quickstart repostiory so it's even more easy to get started!